

Bloodhound is an open source application used for analyzing security of active directory domains. The tool is inspired by graph theory and active directory object permissions. The tool performs data ingestion from Active Directory domains and highlights the potential for escalation of rights in Active Directory domains, thus uncovering hidden or complex attack paths that can compromise security of a network.
The data that can be collected using Bloodhound includes information of users with admin rights as well as if said users are able to access any other computers in the network, and group membership information. All this information can be exploited by an attacker, allowing them to add new users to groups, deleting any current users, adding new admins to the systems, and changing credentials of existing admins.
Setting up Bloodhound
Bloodhound is supported by Linux, Windows, and OSX. Bloodhound depends on Neo4j. Neo4j is a graph database management system. It’s a NoSQL graph database written in Java. Therefore Java is also required to run the Neo4j and ultimately Bloodhound. The purpose of using Neo4j is to visualize the relationship between the information gained through Bloodhound. In Windows operating system, neo4j needs to be installed separately along with the latest version of Java. The Bloodhound framework can then be cloned from the Github using the following command.
git clone https://github.com/adaptivethreat/Bloodhound
In Kali Linux, the installation is different. First we need to update the repositories of the installed apps and upgrade the packages using the following commands.
apt-get update apt-get dist-upgrade
Afterwards, Bloodhound can be installed using the following command.
apt-get install bloodhound
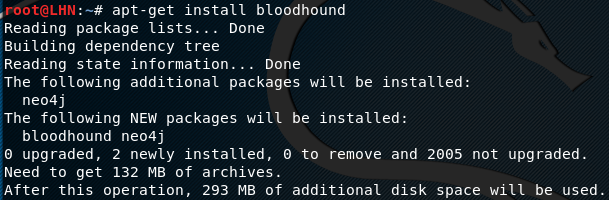
The command not only installs Bloodhound, but also installs the Neo4j package. The next step is to launch and configure Neo4j using the following command.
neo4j console
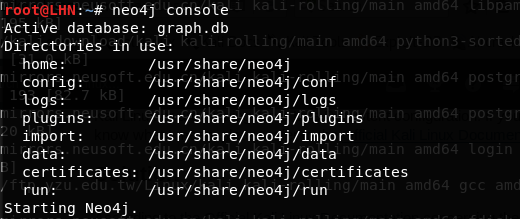
The above command launches Neo4j and establishes a remote interface at http://localhost:7474. Since Neo4j is installed as a default package with Bloodhound, it has a default username and password i-e
Username: neo4j Password: neo4j
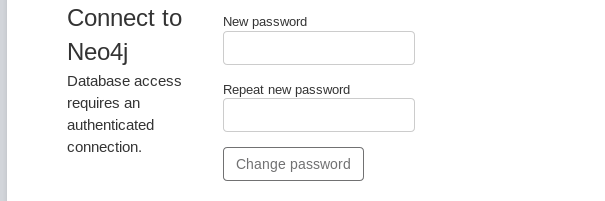
We need to change the default password for security reasons. To change default credentials, open Neo4j database in a web browser by typing the following address:
http://localhost:7474
Once loaded, the Neo4j interface gives option to change the default password.
Analyzing Data with Bloodhound
After configuring Neo4j, open the Bloodhound interface by typing the application in the terminal.
bloodhound
The command prompts for Neo4j database credentials as shown in the following screenshot.
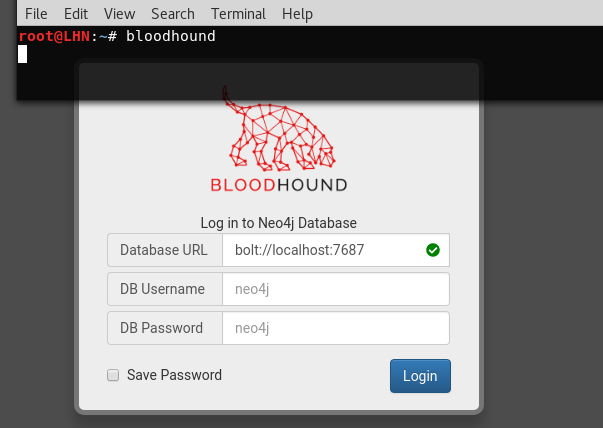
We can see in the screenshot that Bolt is also enabled on the localhost. Bolt is a network protocol used for client server communication. Provide the required credentials to open the Bloodhound interface with Neo4j DB connected. The interface is loaded with different options. On the left side, we can see the database information with some pre-built queries option.
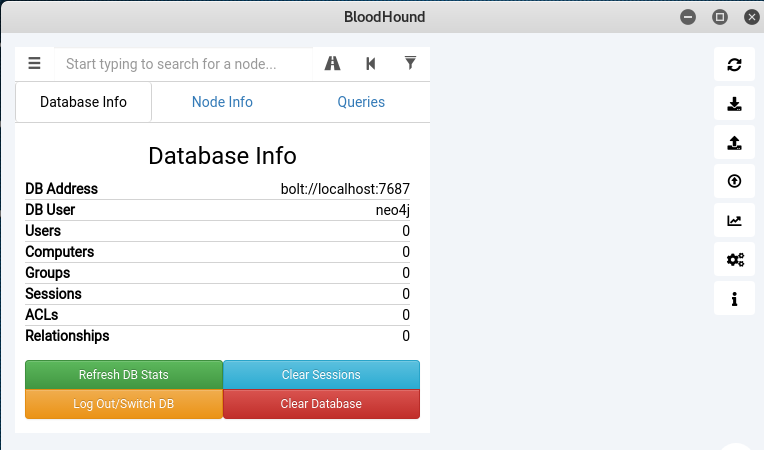
The queries allow analyzing of the data extracted from the target hosts. Besides pre-built queries, custom queries can also be used. On the right side, we have different options like import/export graph, upload data, and thresholds settings. The import/export options are used to import or export the current graphs into JSON format. The upload option is used to feed the data into the Bloodhound interface. It is important to note here that the CSV files are created on the target host containing the information required by Bloodhound. These CSV files need to be uploaded into Bloodhound using the upload option in the Bloodhound interface. Once uploaded, run the desired queries on the data. We can run the custom or pre-built queries on the data from the interface, such as finding all domain admins, finding shortest path to the domain admins, and mapping domain trusts etc. The queries demonstrate the results in a graphical way.
Data Collection Requirements
Bloodhound generally requires three types of information from Active Directory networks. This includes
- Logged in users
- Users with admin rights
- Relationship between the users and the current groups
The above data can be gathered by using the Powershell Ingestor, from the Bloodhound repo.

There is also a Python based ingestor called BloodHound.Py which needs to be manually installed through pip to function. BloodHound.Py currently does not support Kerberos unlike the other ingestor. However, it can still perform the default data collection tasks, such as group membership collection, local admin collection, session collection, and tasks like performing domain trust enumeration.
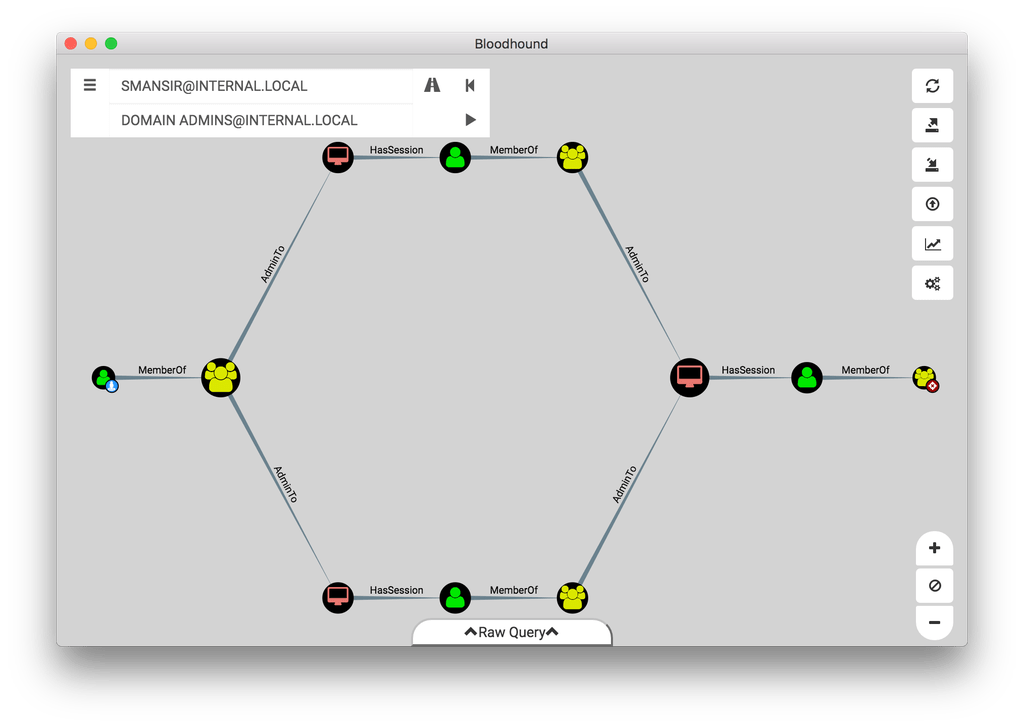
An example of the tools output in mapping a route through administrator machines is shown below:
What Bunny rating does it get?
Bloodhound is a great tool for analyzing the trust relationships in Active Directory environments. The tool identifies the attack paths in an enterprise network that can be exploited for a pen tester to be able to gain domain admin permissions. As a result we will be awarding this tool a rating of 4.5 out of 5 bunnies.

![]()
Want to learn more about ethical hacking?